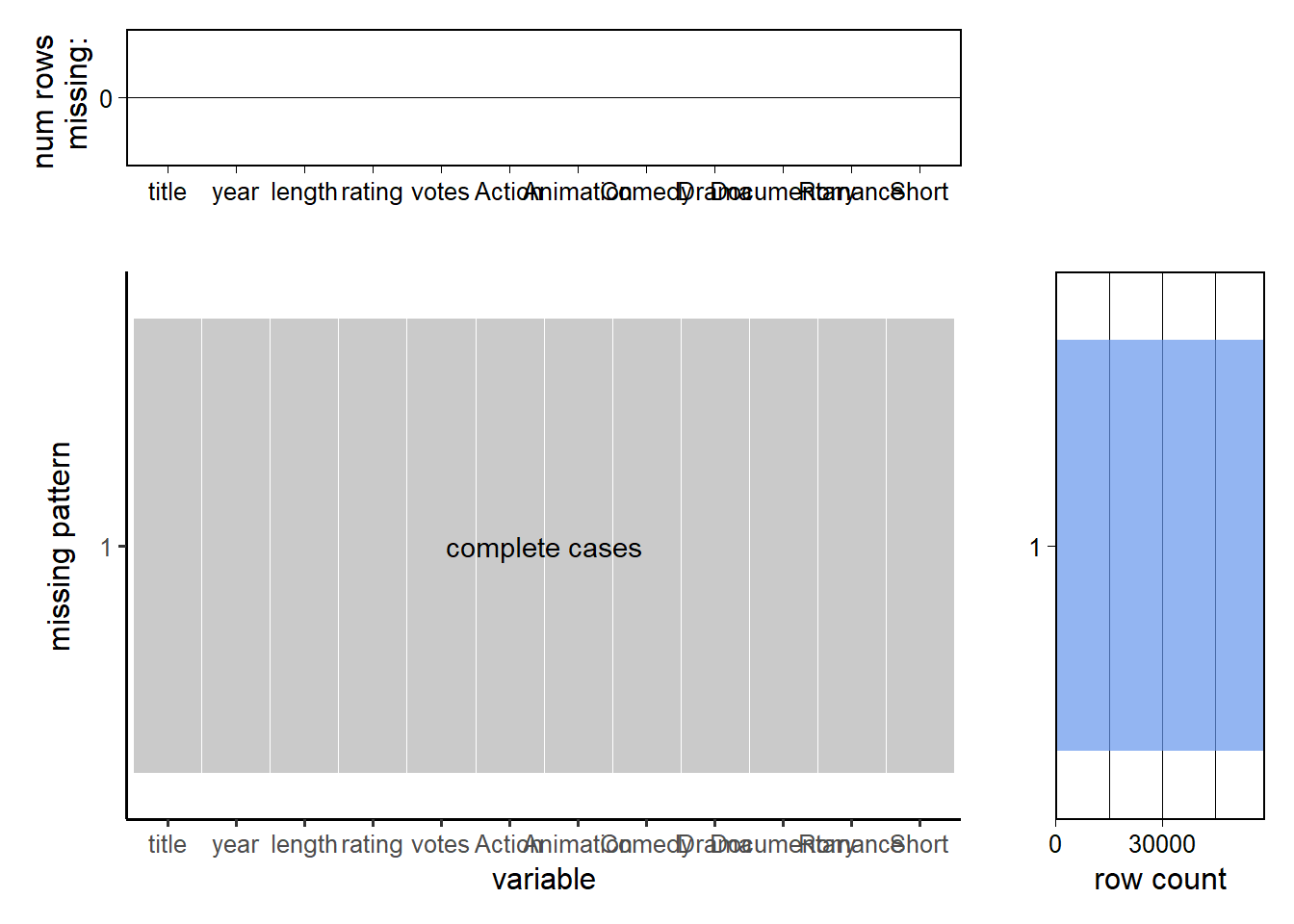
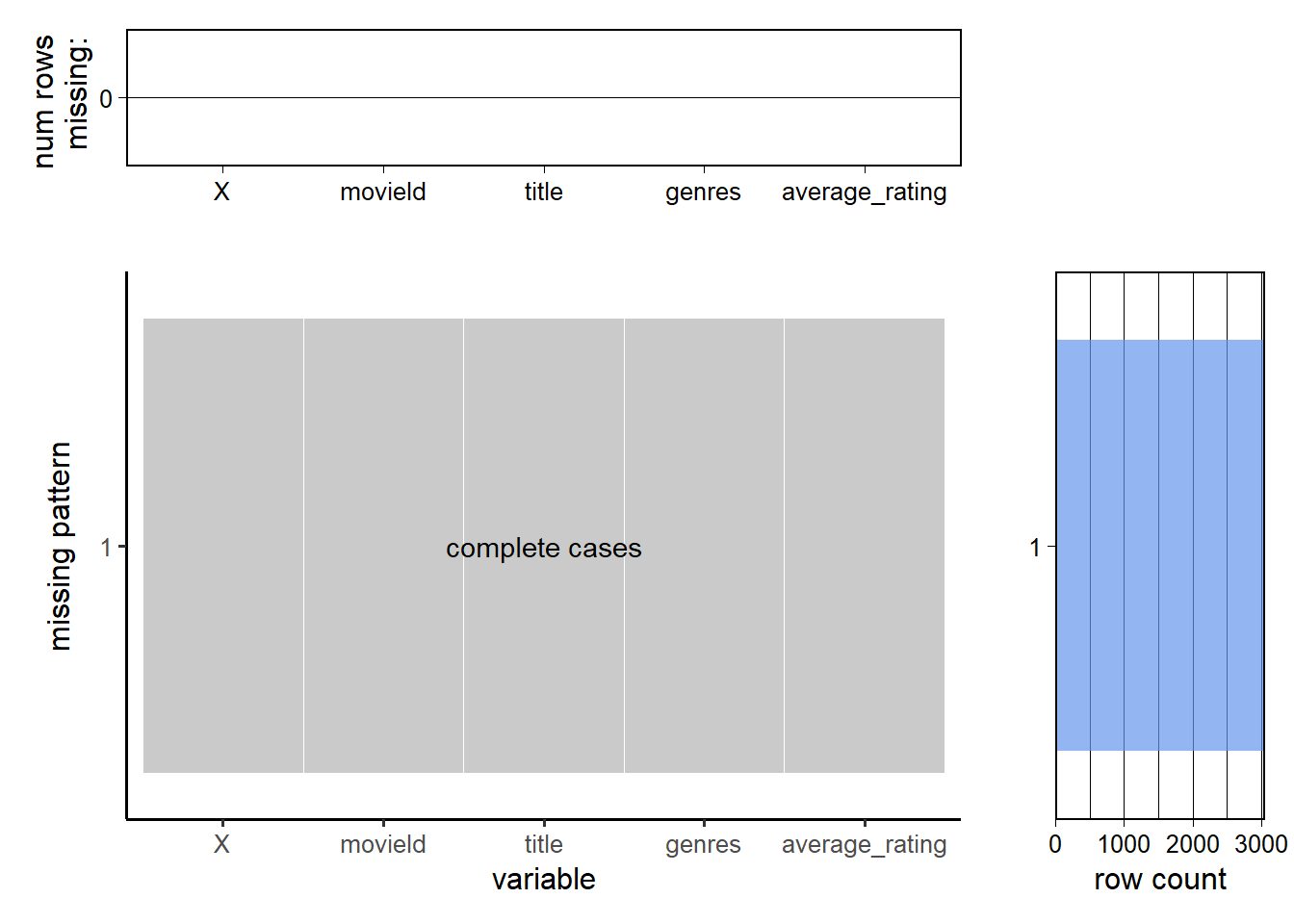
Chapter 3 Data
3.1 Sources
This data is collected by IMDb organization through their users and their user-generated content. Copyright owned by IMDb. We believe IMDb is a reliable source for getting rating information.
We consider using this source because it is one of the biggest movie database on the web and is collected directly from the users. In addition to movie ratings, it also provides information such as the title, length, release year, genres associated with the title, number of votes, etc.
We choose to import this data by using the ggplot2movies package in R directly since it is the easiest way. The data is published on 2015-08-25 and the maintainer is Hadley Wickham. The dataset contains 58,788 rows and 24 columns. Each column is either character type or numeric/integer type. Movie genres (“Action”, “Animation”, “Comedy”, “Drama”, “Documentary”, “Romance”, “Short”) are one-hot encoded and there exists movies with more than one genres.
These datasets were collected from MovieLens by GroupLens. GroupLens is a research lab in the Department of Computer Science and Engineering at the University of Minnesota. There were 162541 users selected, and users were selected at random. All selected users had rated at least 20 movies. Because the variety and number of movies in this dataset are large, the results we got from this dataset would be more accurate and more convincing.
This dataset was generated on November 21, 2019. There are 6 different datasets generated, which contain over 25 million ratings across 62423 movies and their genres. We would mainly focus on movie.csv and rating.csv. We import the datasets by ‘read_csv’ in the ‘readr’ package and combine the two tables by movies’ unique ID (using the “movieId” column).
There are 25000095 rows and 4 columns in rating.csv and all the columns are numeric/integer type. Each row represents one rating of a movie rated by one user. There are 62423 rows and 3 columns in movies.csv and the columns are either character or numeric/integer type. One movie can have multiple genres, and each genre name is separated by “|” coded in one column. And we first need to separate these genres into different columns.
3.2 Cleaning / transformation
Two data sets are used in this project, we will discuss them separately.
3.2.1 IMDb Datasets
Take a look of the original data which is messy.
## # A tibble: 6 × 24
## title year length budget rating votes r1 r2 r3 r4 r5 r6 r7 r8 r9
## <chr> <int> <int> <int> <dbl> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 $ 1971 121 NA 6.4 348 4.5 4.5 4.5 4.5 14.5 24.5 24.5 14.5 4.5
## 2 $1000 a… 1939 71 NA 6 20 0 14.5 4.5 24.5 14.5 14.5 14.5 4.5 4.5
## 3 $21 a D… 1941 7 NA 8.2 5 0 0 0 0 0 24.5 0 44.5 24.5
## 4 $40,000 1996 70 NA 8.2 6 14.5 0 0 0 0 0 0 0 34.5
## 5 $50,000… 1975 71 NA 3.4 17 24.5 4.5 0 14.5 14.5 4.5 0 0 0
## 6 $pent 2000 91 NA 4.3 45 4.5 4.5 4.5 14.5 14.5 14.5 4.5 4.5 14.5
## # … with 9 more variables: r10 <dbl>, mpaa <chr>, Action <int>, Animation <int>, Comedy <int>,
## # Drama <int>, Documentary <int>, Romance <int>, Short <int> In this data set, each genre type of movies is set to a variable. However, they are not different variables, they should be values of a common variable “genres”. Thus, we use pivot_longer to transform the data. (We only display columns that shows the transformation here.)
## # A tibble: 6 × 3
## title rating genres
## <chr> <dbl> <chr>
## 1 $ 6.4 Comedy
## 2 $ 6.4 Drama
## 3 $1000 a Touchdown 6 Comedy
## 4 $21 a Day Once a Month 8.2 Animation
## 5 $40,000 8.2 Comedy
## 6 $pent 4.3 Drama The columns r1-10 give percentile of users who rated this movie a 1. Since we are exploring the impact of personal interests on movies’ rating, we don’t mind extreme or biased ratings. So we will ignore these variables.
Also, we believe that the movies rated by less than 200 IMDB users are unrepresentative, so we use filter() on the column “votes” to remove those movies.
3.2.2 MovieLens 25M Dataset
We would mainly focus on the files movie.csv and rating.csv. There are 25 million rows and 4 columns in rating.csv, each row represents one rating of a movie rated by one user. There are 62423 rows and 3 columns in movies.csv, one movie can have multiple genres, and each genre name is separated by “|” coded in one column.
Since the original data files are too large to upload and lead to overplotting, we decide to only process a random sample of them by using slice_sample().
The ratings and genres of a movie are in separate files, so we need first combine the two data sets by movies’ ID which is unique and consistent. For every movie, we obtain a lot of scores rated by different users, we choose to compute the average rating for each movie.
## X movieId title genres average_rating
## 1 1 175661 The Hitman's Bodyguard (2017) Action|Comedy 4.291667
## 2 2 4020 Gift, The (2000) Thriller 3.250000
## 3 3 2865 Sugar Town (1999) Comedy 3.000000
## 4 4 73232 Girl in the Park, The (2007) Drama 4.000000
## 5 5 2878 Hell Night (1981) Horror 2.300000
## 6 6 2348 Sid and Nancy (1986) Drama 3.478261 As we can seen, one movie can have multiple genres, and each genre name is separated by “|” coded in one column. Since we are exploring the impact of genres on ratings, we separate those movies into different rows that each contains only one type of movie genres. Finally, we obtain the clean data that we’ll work with in the following parts.
## # A tibble: 6 × 5
## X movieId title genres average_rating
## <int> <int> <chr> <chr> <dbl>
## 1 1 175661 The Hitman's Bodyguard (2017) Action 4.29
## 2 1 175661 The Hitman's Bodyguard (2017) Comedy 4.29
## 3 2 4020 Gift, The (2000) Thriller 3.25
## 4 3 2865 Sugar Town (1999) Comedy 3
## 5 4 73232 Girl in the Park, The (2007) Drama 4
## 6 5 2878 Hell Night (1981) Horror 2.3